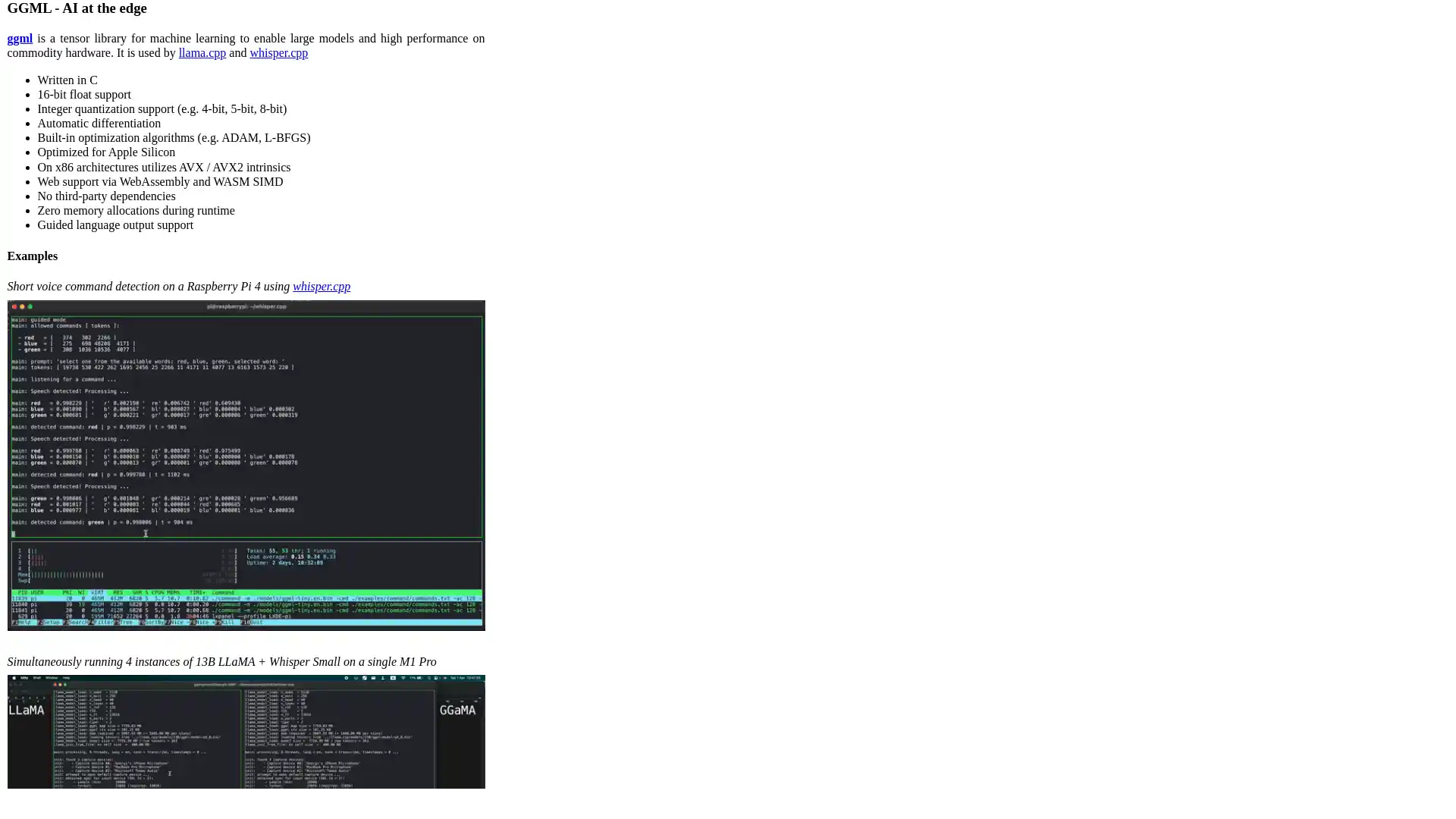
GGML
Tags:
#AI Detection
#Speech-To-Text
Why to Use This AI Tool?
GGML is a tensor library for machine learning that enables large models and high performance on commodity hardware. It supports 16-bit float and integer quantization, automatic differentiation, and built-in optimization algorithms. It is optimized for Apple Silicon and has web support via WebAssembly and WASM SIMD. It has no third-party dependencies and zero memory allocations during runtime. It includes two projects: whisper.cpp for high-performance speech-to-text and llama.cpp for efficient inference on Apple Silicon hardware. The project is open core and encourages contributors to try crazy ideas and build wild demos.How to Visit This AI Tool Website?
https://ggml.ai/How the AI tool Website Looks Like?